当ページのリンクには広告が含まれています。
本記事では、LSTM(Long short-term memory)というRNNの拡張モデルを活用して、サンドウィッチマンさんの漫才ネタを学習させて、もっともらしい単語の予測をさせてみました。
目次
LSTMとは
以下の記事で詳細にまとめられています。
https://qiita.com/t_Signull/items/21b82be280b46f467d1b
LSTM(Long short-term memory)は、RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データ(sequential data)に対するモデル、あるいは構造(architecture)の1種です。その名は、Long term memory(長期記憶)とShort term memory(短期記憶)という神経科学における用語から取られています。LSTMはRNNの中間層のユニットをLSTM blockと呼ばれるメモリと3つのゲートを持つブロックに置き換えることで実現されています。
要するにRNNの中間層がLSTM層に置き換わったものであるということです。
LSTM層の内部には、記憶セル、入力ゲート、出力ゲート、忘却ゲートという内部要素を保持しており、複雑に絡み合っております。
しかしながらPythonのKerasを用いることでシンプルに実装することができます。
なお、RNNについては以下の記事でまとめているので参考にしてください
入力データの準備
今回は、サンドイッチマンさんの漫才ネタをテキストデータとして用意したものを使います。
その中でも私個人的に好きな、ハンバーガー屋のネタ、弔事のネタ、旅行代理店のネタの3つを、テキストで書いたものです。
以下のような感じです・
sand_manzai.txt1
2
3
4
5
| あら。昨日の夜まで何もなかったのに、急にハンバーガー屋出来てるな。興奮してきたな。ちょっと入ってみようか。いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!ブックオフか。うっせぇ、何回も。1回でいいんだよ、1回で。こちらでお召し上がりですか?いや、持って帰るよ。ソルトレイクの方で…。テイクアウトだよ。なんだソルトレイクって。なんで俺冬季オリンピックなんだ。持って帰る、持って帰る。…メニュー、メニュー。お客さん。踏んでますよ。なんで下にあんだよ。
(略)
婚活パーティーか、お前。金取れ、女からも。バカたれ!さっ!というわけでねっ。そろそろお時間となってしまいました。何でラジオの終わりみたいになってんの。おかしい。DJみたいになってんじゃん、急に。ホントにねっ。まろやかに眠ってもらいたいです。いやいや。やすらかにだよ、やすらかに。まろやかにってお前、クリープかお前。それではまた、来週のこの時間まで!さようならぁ~!来週もやんのかよ。どういうことだよ、これお前。こんな感じでどうかな?全部書き直せ。もういいぜ。
|
ハンバーガー屋のネタから弔事のネタまでを、ただ単にテキストで書き連ねただけのデータです。
データの読み込み
まずは、このテキストデータをJupyter Notebook環境に読み込みます。
読み込むテキストデータは、実行している.ipynbファイルと同じフォルダに配置しましょう。
1
2
3
4
5
6
7
8
| import re
with open("sand_manzai.txt", mode="r", encoding="utf-8") as f:
sand_original = f.read()
sand = re.sub("[\n]", "", sand_original)
print(sand)
|
これで、テキストデータが表示されればOKです。
時系列の数、バッチサイズ、エポック数、中間層のニューロン数の設定
この辺りの値は、実験を繰り返しながら最適な値を設定しました。
以下は、何回か実験を繰り返した結果の最終的な値です。
1
2
3
4
| n_rnn = 10
batch_size = 128
epochs = 60
n_mid = 256
|
入力データに対する時系列の数やバッチサイズって、どのように設定するのがベストプラクティスなのかは、勉強中です。。。
以下の記事によると、少しばかりヒントがありました。
https://www.st-hakky-blog.com/entry/2017/11/16/161805
よく論文で見るBatch size
Deep Learningの論文を読んでいるとどうやって学習をさせたかみたいな話はほぼ乗っているので、そういうのを見ていてよく見かけるのは以下あたりではないかと思います(すみません、私の観測範囲ですが)。
- 1
- 32
- 128
- 256
- 512
だいたい、1だと完全に確率的勾配降下法になりますし、512だと学習速度をあげたかったのかなという気持ちが見えます。このあたりについてどれにするべきかというところを考察してみたいと思います。
各文字のベクトル化
各文字をone-hot表現にします。one-hot表現を用いることで、単語をニューラルネットワークで扱いやすいベクトルの形にすることができます。
各文字をone-hot表現にするには、以下のように処理を行います。
- 文字の重複を省きlist化
- 文字がキーでインデックスが値の辞書を作成
- インデックスがキーで文字が値の辞書を作成
- 入力と正解をone-hot表現に変更する
文字の重複を省きlist化
まずは、setを使って文字の重複を省き、listにして、sortしたものをcharに格納したいと思います。
1
2
3
4
5
6
7
| import numpy as np
chars = sorted(list(set(sand)))
print(chars)
print("文字数(重複なし)", len(chars))
|
文字がキーでインデックスが値の辞書を作成
次にchar_indicesという空の辞書を作成し、そこにループでインデックスi, 各文字をcharに格納。
char_indicesのキーとしてcharを指定してiを格納することで、文字がキーでインデックスが値の辞書が完成します。これは後程使います
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| char_indices = {}
for i, char in enumerate(chars):
char_indices[char] = i
char_indices
|
インデックスがキーで文字が値の辞書を作成
次に、indices_charというインデックスがキーで文字が値の辞書を作成します。こちらも後程使います。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| indices_char = {}
for i, char in enumerate(chars):
indices_char[i] = char
indices_char
|
時系列データと予測する文字の抽出
時系列データはtime_chars、予測する文字はnext_charsに格納します。
テキストの長さから時系列の長さをを引いた分だけループを実施。
time_charsにはテキストのi~i+n_rnn分の長さだけの文字を加えてあります。これで時系列の数の回数分だけ再帰処理する時系列データを用意できます。
next_charsにはtime_charsから予測すべき文字なので、i + n_rnn番目の文字をリストに格納しています。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| time_chars = []
next_chars = []
for i in range(0, len(sand) - n_rnn):
time_chars.append(sand[i: i + n_rnn])
next_chars.append(sand[i + n_rnn])
time_chars
next_chars
|
入力と正解をone-hot表現で表す
ここで、入力\(x\)と正解\(t\)を作っています。最初はzerosすべての要素を0にします。
入力\(x\)の形状は、[time_charsの長さ、時系列データの長さ(n_rnn)、文字数]、となります。今回は、要素は0か1の二通りしかありませんので、データのタイプはbool型にしておきます。
また、正解\(t\)ですが、こちらは、[time_charsの長さ、文字数]、の形状にします。こちらも同様にデータのタイプはbool型にしておきます。
time_charsの数だけまずループを行います。 まず、正解に対して値を設定。
indexがiで各要素がt_csになるわけですが、正解な文字が入っているnext_charsから文字を取り出し、char_indicesによりindexに変換します。
そして、その要素を1に設定します。
これにより、この要素のみ1で、あとは0になるone-hot表現に変換されることになります。
また、入力の方は、さらにループの入れ子構造を使って設定します。
t_csを使ってループを行っており、この際のインデックスはj, 要素はcharとします。
\(x\)のiとjを設定して、そのうえでchar_indicesを使って文字をインデックスに変換します。
この要素を1にします。
こうすることで、入力も同様にone-hot表現で表すことが可能です。
試しに、xを出力してみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| x = np.zeros((len(time_chars), n_rnn, len(chars)), dtype=np.bool)
t = np.zeros((len(time_chars), len(chars)), dtype=np.bool)
for i, t_cs in enumerate(time_chars):
t[i, char_indices[next_chars[i]]] = 1
for j, char in enumerate(t_cs):
x[i, j, char_indices[char]] = 1
x
t
|
xとtの形状も確認してみます。
1
2
3
4
| print("xの形状", x.shape)
print("tの形状", t.shape)
|
これでone-hot表現化は完了です。
LSTMモデルの構築
Kerasを使ってLSTMを構築していきます。
SimpleRNN層と同じ方法で構築できます。
損失関数は、複数の分類に適したcategorical_crossentropyを指定し、最適化アルゴリズムは収束しやすいadamを指定したいと思います。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| from keras.models import Sequential
from keras.layers import Dense, LSTM
model_lstm = Sequential()
model_lstm.add(LSTM(n_mid, input_shape=(n_rnn, len(chars))))
model_lstm.add(Dense(len(chars), activation="softmax"))
model_lstm.compile(loss='categorical_crossentropy', optimizer="adam")
print(model_lstm.summary())
|
文書を生成するための関数を記述し学習
各エポックが終了した際に、文章を生成するための関数を作成します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| from keras.callbacks import LambdaCallback
def on_epoch_end(epoch, logs):
print("エポック: ", epoch)
beta = 5
prev_text = sand[0:n_rnn]
created_text = prev_text
print("シード: ", created_text)
for i in range(400):
x_pred = np.zeros((1, n_rnn, len(chars)))
for j, char in enumerate(prev_text):
x_pred[0, j, char_indices[char]] = 1
y = model.predict(x_pred)
p_power = y[0] ** beta
next_index = np.random.choice(len(p_power), p=p_power/np.sum(p_power))
next_char = indices_char[next_index]
created_text += next_char
prev_text = prev_text[1:] + next_char
print(created_text)
print()
epock_end_callback= LambdaCallback(on_epoch_end=on_epoch_end)
model = model_lstm
history_lstm = model_lstm.fit(x, t,
batch_size=batch_size,
epochs=epochs,
callbacks=[epock_end_callback])
|
LambdaCallbackは、エポック終了時等のタイミングで、特定の処理を行うための関数として使用します。
betaという定数が設定されています。これは確率分布を調整する定数です。
確率分布を使用する意図は、最も確率が高い文字だけではなく、それ以外の文字からも確率に従いサンプリングをするためです。結果的に、高い確率の文字が選ばれる頻度が高くなります。これは、入力データに対して、次の文字として最も確率の高い文字を予測する代わりに、確率分布を推定する、ということになります。
prev_textには、テキストの最初から時系列分だけを取り出したサンドウィッチマンのネタの文字列が入ります。これが、モデルに入力される文字列になり、常に直近の時系列データが入るようにします。
created_textは、生成されるテキストです。文章は必ず、prev_textから始まるようにするので、prev_textを入れておきます。そして、created_textがシードになります。これがベースとなって次々と次の文字を予測していくことになります。
今回は400文字の文章を生成する。
入力をone-hot表現に変換するために、入力x_predには、まずnp.zerosで初期化したものを含める。サンプル数が1, 時系列データ, charsの数の形状をしています。
次に予測を行っていきます。
model.predictに、x_predを入れて出力のyを得ることができます。
y[0]で各文字に対応する確率分布のリストが得られる。これにbetaを累乗。betaの値は、1より大きいと高い確率がより高くなるように確率分布が調整されます。
次の文字として、next_indexに、特定の確率分布の中からサンプリングされた値(文字のインデックス)が代入される。確率分布pは、p_powerに対して、P_powerを足し合わせたもので割っている。これは、確率分布pが、すべて足しあわされて1にならなければならないためです。
確率分布については、以下のchainerチュートリアルのドキュメントが分かりやすいと思います。
https://tutorials.chainer.org/ja/06_Basics_of_Probability_Statistics.html
そして、next_indexをキーとして、indices_charに入れることで、次の文字を取り出すことができる。
prev_textは、最初の文字を取り除き、next_charを加えることで、直近の時系列に更新される。
このようにして訓練済みのLSTMのモデルを使って、文章を自動生成することができる。
学習の推移を確認していくと徐々にサンドイッチマンのネタに近づいていきます。途中ずっと「いらっしゃいませこんにちは!」しか言わなったりしますが、、、
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| Epoch 1/60
5408/5408 [==============================] - 14s 3ms/step - loss: 5.3819
エポック: 0
シード: あら。昨日の夜まで何
あら。昨日の夜まで何ないかんんーんーんんいい。い。ないいいんい、ん、っいんかいんいなかいおいんっん。いかていい、っい、たんな、、いいだのいいいんんいてお、ない、いんーいーいいーーい、いんい。っい、で、ー、いいーー、いいな、。ん、いいなんんいー、ーーいいいんていっおんいいっなんんいーーあ、、ん。だーんんいんん、、んおんい、っない、ー、いっいい、いいいい、ら、んかんん。っないかいいー、。っん、いおおいて、っいっ、いいいー、かんおおーいていん、、んんいいいいすん、おーーー、いい、いい、いんっー、っっいいーーいってんいいいーんいい、ーんいのし、なんんい、、んっいすっんーてーんてーいっなのいーい、、いっ、い、、いんっー。、のなー、いんー、っ、いっ。んいておいいーよいん、んー、ーなー、い、、っんい、いんないんだっ、か、いーなん、、っっいんーてーんいおいんうでいで、んーの。い、、のんんい。ーおしっ、いんんんいんいーいいん。
Epoch 10/60
5408/5408 [==============================] - 11s 2ms/step - loss: 4.1347
エポック: 9
シード: あら。昨日の夜まで何
あら。昨日の夜まで何たたいたいんだよ。。あ、、ののののに・・のにいににいっててん。。。んのく、のののののにののすののですかか?。か?か、、。ちののにののしのの、、いすに。ののののーー、だ、よ。。、れののの方にののにしにいってん。。。ちちののののの、いのののにしにいてんだよ。。あちれしっての。。。あ、、ののにののの方になのたっててん。。。の、のののののの・・・・・で・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・、・・・・・・・・・・・・・の・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・の・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・・
Epoch 20/60
5408/5408 [==============================] - 12s 2ms/step - loss: 2.5751
エポック: 19
シード: あら。昨日の夜まで何
あら。昨日の夜まで何ですかかもにりだよ。おっていいます。何や、ロオーー。そー、知れ。これ、お前。あー、ううらううう。あれ、あうです。やうやでしうから、お前。ないまですか?やや、だオー。ララララ見にてってるてよかな。でんですか?いいんだよ。お前、ちゃんだよ。いいいです。何やからだー、お前。何ですか??いわ、、なん。持持ちてよ、お前。えってんでよ。どうううってんだよ。あン、これになんだよ。お前、あ、、お前。きやきうららいます。あ、ですも。ううーうう!!!れンンううううう!!ンンンンンンンン!ンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンンン
Epoch 44/60
5408/5408 [==============================] - 12s 2ms/step - loss: 0.2862
エポック: 43
シード: あら。昨日の夜まで何
あら。昨日の夜まで何もなかったのに、急にハンバーガー屋出来てるな。興奮してきたな。ちょっと入ってよねうか。お前、あットババナナェイェイで…いやサイでです。こいなににこんらくくちゃいていのお前。なー、じゃあの、こンにに北おおかしなあ。バー。繰イ人人、お前。あ、で婚の人お前っなんか。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言ってるか分かんない。何で何言
Epoch 49/60
5408/5408 [==============================] - 12s 2ms/step - loss: 0.1811
エポック: 48
シード: あら。昨日の夜まで何
あら。昨日の夜まで何もなかったのに、急にハンバーガー屋出来てるな。興奮してきたな。ちょっと入ってみようか。いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにちはー!いらっしゃいませこんにち
Epoch 60/60
5408/5408 [==============================] - 12s 2ms/step - loss: 0.0870
エポック: 59
シード: あら。昨日の夜まで何
あら。昨日の夜まで何もなかったのに、急にハンバーガー屋出来てるな。興奮してきたな。ちょっと入ってみようか。いらっしゃいませこんにちはー!ブックオフか。うっせぇ、何回も。1回でいいんだよ、1回で。こちらでお召し上がりですか?いや、持って帰るよ。ソルトレイクの方で…。テイクアウトだよ。なんだソルトレイクって。なんで俺冬季オリンピックなんだ。持って帰る、持って帰る。…メニュー、メニュー。お客さん。踏んでますよ。なんで下にあんだよ。上に置いとかな全然見えなかったわ、お前。あー、どうしようかな。じゃあ、ビッグバーガーセットはいかがですか?太るわ。普通なんかサイドメニューみたいな。サイドメニュー?ご一緒に(※ポテトの発音で)ホタテになります。(※ポテトの発音で)ホタテに!あ、いらっしゃちいま。あとち言ーにますらか。な一ににつらっていませま。。あもですぎ。1ぇの!ういいや!11回!(※でも1をを指両両両のををンン指指を指を
|
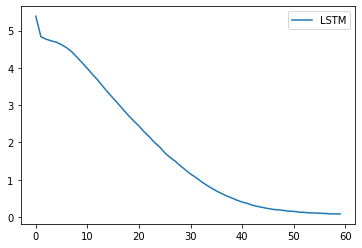
誤差の収束具合をグラフで確認します。
1
2
3
4
5
6
7
8
| %matplotlib inline
import matplotlib.pyplot as plt
loss_lstm = history_lstm.history['loss']
plt.plot(np.arange(len(loss_lstm)), loss_lstm, label="LSTM")
plt.legend()
plt.show()
|

ちゃんと誤差が収束に向かっているのが分かります。
まとめ
LSTMの理解を深めるために、サンドウィッチマンのネタを学習し予測させてみました。
様々なデータに活用し、実験してみていただけると幸いです。
RNNやLSTMを構築して自然言語処理を学びたい方は、以下のUdemy講座がおすすめです。
本記事の作成においても、とても参考にさせていただきました。30日以内では返金保証が効くので無料で講座の内容を確認することが出来ます。
>>自然言語処理とチャットボット: AIによる文章生成と会話エンジン開発