【5分で分かる】データモデルとデータベースの設計方法と関係性

当ページのリンクには広告が含まれています。

本記事では、「【5分で分かる】データモデルとデータベースの設計方法と関係性」というテーマでまとめていきます。
目次
- 本記事の対象者
- データ/データベースとは何か
- データベースを作成する一連の過程:「データモデリング」
- リレーショナルデータベースの弱点と「NoSQL」
- まとめ:データべースの設計はデータモデリングが大事
本記事の対象者
- 「データモデル」って何?という人
- データモデリングってどのような手順で考えればいいの?という人
- データベースを設計する際に気をつけるポイントを知りたい人
データ/データベースとは何か
「データ」とは、実際に存在するものを文字や数字や画像など、コンピュータ上で表現したものです。
例えば、「住所」、「氏名」、「年齢」などがデータに相当します。
そして、データの集合体のことを「データベース」と言います。ITの業界では、「DB」と略されることが多いです。
データベースを作成する一連の過程:「データモデリング」

データベースを作成するまでの一連の過程を「データモデリング」といいます。
データモデリングでは、実際の業務をシステム化するために、必要なデータ項目を整理して可視化します。
データベース構築の流れ、すなわちデータモデリングは、以下のとおりです。
2. データベースで管理すべき項目を洗い出す
3. 各データベースに合わせて設計する
そして、1~3の各工程で作成した情報が、「データモデル」です。
以降では、データモデリング工程である1~3の内容と、作成されるデータモデルについてまとめていきます。
データベース構築の工程その1: 企業の業務の全体像を把握する
データベースを設計するためには、対象となる業務の流れを調査・分析し、理解する必要があります。
例えば、お客様の注文情報管理システムを作成するといった要望があった場合、お客様の注文情報をデータ化するだけではシステムは作れません。
お客様の注文を管理するためには、注文を受けた商品の在庫を確認する業務や、発送する業務といった業務の流れが存在します。
このように業務の流れを調査し、全体像を理解することがデータベースを作成するためには必要です。
この際、細かい業務までを把握する必要はありません。
その業務において重要な業務を抽出すれば良いのです。
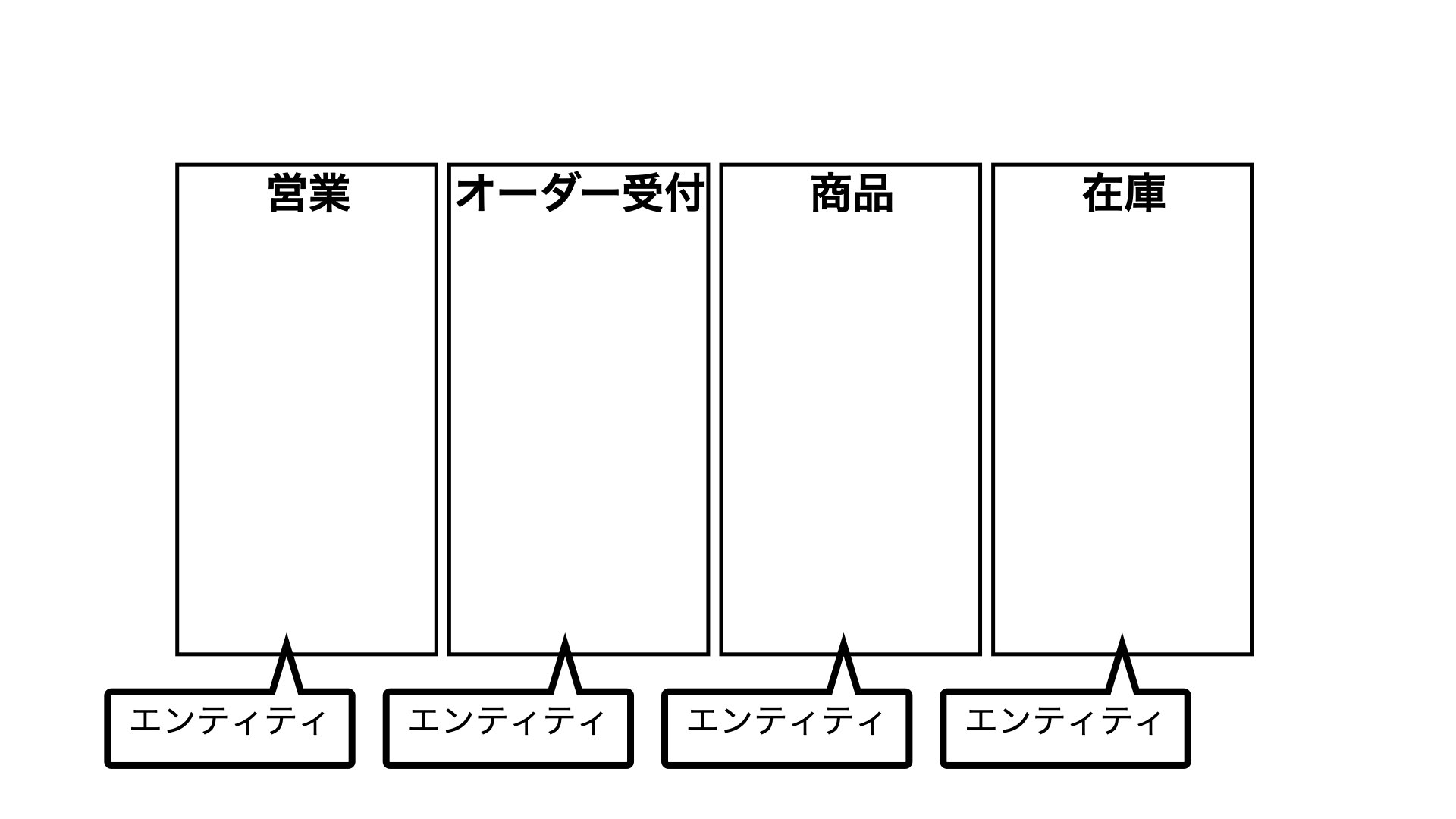
例えば、「営業」、「オーダー受付」、「商品」、「在庫」、、という具合です。
このように、「営業」、「オーダー受付」など、企業にとって重要な一つ一つの業務のことを「エンティティ」と言います。
そしてエンティティを抽出したものを「概念データモデル」といいます。
データベース構築の工程その2: データベースで管理すべき項目を洗い出す
概念データモデルにより業務の全体を把握できたら、データ化する業務や項目をまとめていきます。
具体的には、「エンティティ」、「属性」、「各テーブルのリレーションシップ」を決定していきます。
例えば、「オーダー受付」と「商品」というエンティティをデータ化する場合で説明します。
まず「オーダー受付」という業務を行う上で、どのようなデータが必要なのかを整理します。
必要なデータを、ここでは仮に、「オーダーID」、「オーダー日時」、「顧客ID」だとします。
この「オーダーID」、「オーダー日時」、「顧客ID」それぞれを、「属性」と言います。
次に、各属性間の関係を整理します。
各属性間の関係は、特定の属性が他のエンティティにどれだけ紐付いているのかを線で結ぶことで整理します。
例えば以下のように、「オーダーID」という属性が商品というエンティティにも紐付いていることを示すことで、各エンティティ間の関係性を可視化します。
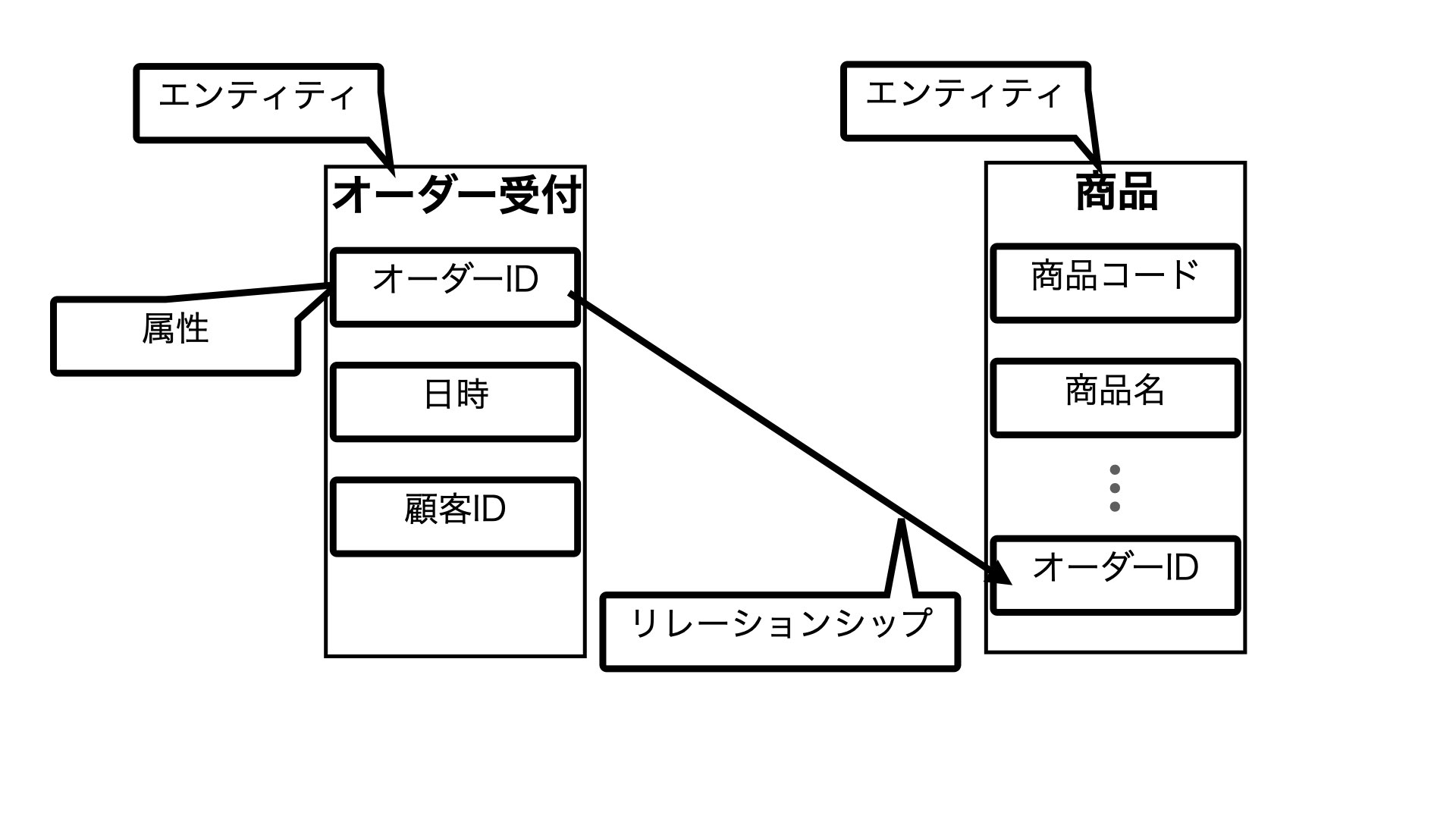
この関係性を「リレーションシップ」と言います。
以上のように、各エンティティにおける属性、リレーションシップが定義されたものを、「論理データモデル」と言い、論理データモデルによって、データ化する業務や項目を可視化することができるのです。
論理データモデルをまとめていく際の注意点としては、データ型などの細かい定義を行わないことです。
この段階では、まずは、MySQLといったデータベース管理システムに依存しないレベルで項目を洗い出していくことを前提にしましょう。
また、論理データモデルには、いくつか種類があります。
それぞれの特徴を簡単に紹介したいと思います。
論理データモデルの種類: ①階層型データモデル(木構造)
階層型データモデルとは、データを親子関係で管理するモデルです。
階層構造の特徴は、1対多の関係にしか対応できない制約があります。
階層構造を満たすデータしか対応できませんが、階層構造のデータであれば高速で検索することが可能になります。
論理データモデルの種類: ②ネットワーク型データモデル
ネットワーク型データモデルとは、子データが複数の親データを持っているデータモデルのことです。
ネットワーク型データモデルは、多対多を表現することができます。
階層型データモデルに比べて、より複雑なデータモデル作成することが可能ですが、構造が複雑になりすぎる点がデメリットになります。
論理データモデルの種類: ③リレーショナルデータモデル
リレーショナルデータモデルは、行と列によって構成された表のようなモデルのことです。
現在最も利用されているデータモデルであり、見やすく扱いやすいことに加え、複雑なデータ構成にも対応することができます。
データベース構築の工程その3: 各データベースに合わせて設計する
実装フェーズに向けた詳細設計を進めていきます。
定義することは、各属性のデータ型、テーブル構成が主になります。
最も一般的に使われているデータベースは「リレーショナルデータベース」というデータベースです。
リレーショナルデータベースとは、データを表(テーブル)で管理するデータベースであり、行と列の組み合わせによってデータを管理しています。
このリレーショナルデータベースを管理するのが、RDBMSと呼ばれる「リレーショナル型データベース管理システム」というものです。
データの型やデータの構造の設計は、使用するRDBMSが定義するデータの型やデータ構造を前提に設計しなければなりません。
RDBMSにはいくつか種類があります。
- Oracle DataBase
米国のIT企業「Oracle」が開発しているデータベース。オンプレミスでもクラウドでも利用することができ、リレーショナル、グラフ、構造化および非構造化リレーショナルなどの全てのデータ型をサポートします。企業など、大規模システム開発で利用されることが多いデータベースです。
- MySQL
米国のIT企業「Oracle」が開発したRDBMSです。MySQLは、無料のオープンソースのデータベースです。無料でありながらも大規模なWebシステムにも対応することができます。
- SQLServer
SQLServerは、MicroSoftが提供するRDBMSです。Windowsとの相性が良く、UIもわかりやすいのが特徴です。GUI上の操作でデータベースを管理することができます。小規模な開発から大規模な開発まで対応できます。
データベースの設計ポイント

ここではリレーショナルデータモデルを例に、基本的な設計の考え方や設計方法をまとめていきます。
リレーショナルデータモデルは、二次元の表であり、この二次元の表を「テーブル」と呼びます。
テーブルは、「カラム」、「レコード」、「フィールド」で構成されています。
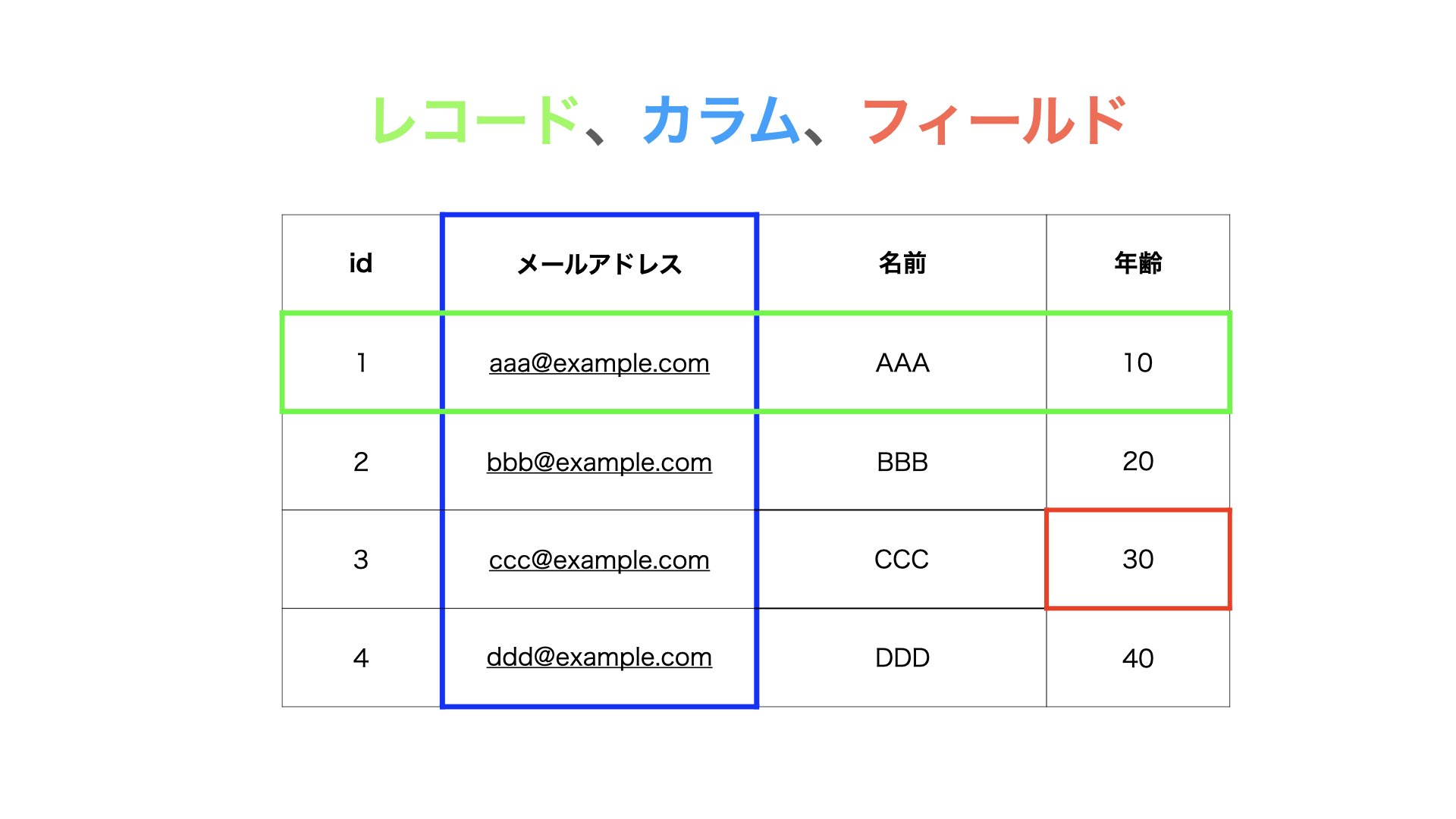
こちらのテーブルを例に、テーブルのリレーションの考え方・ポイントについて解説します。
仮にこのテーブルに、「部署」という情報も加えたいとなった場合、どうすればよいでしょうか?
まず考えられるのは、新たに「部署」というカラムを作るというやり方が考えられます。

このように「部署」というカラムを作った後、例えば「HR」という部署名を変えたいとなった場合、どうなるでしょうか。
「HR」という文字列を、「Planning」に変更するとき、2箇所のフィールドを変更しなければなりません。
2つくらいであれば良いですが、これが100とか。1000とかになったらどうなるでしょうか?
多くの処理が必要になり大変です。
これを防ぐためには、「部署テーブル」という新たなテーブルを作成し、「部署ID」をもたせれば良いのです。
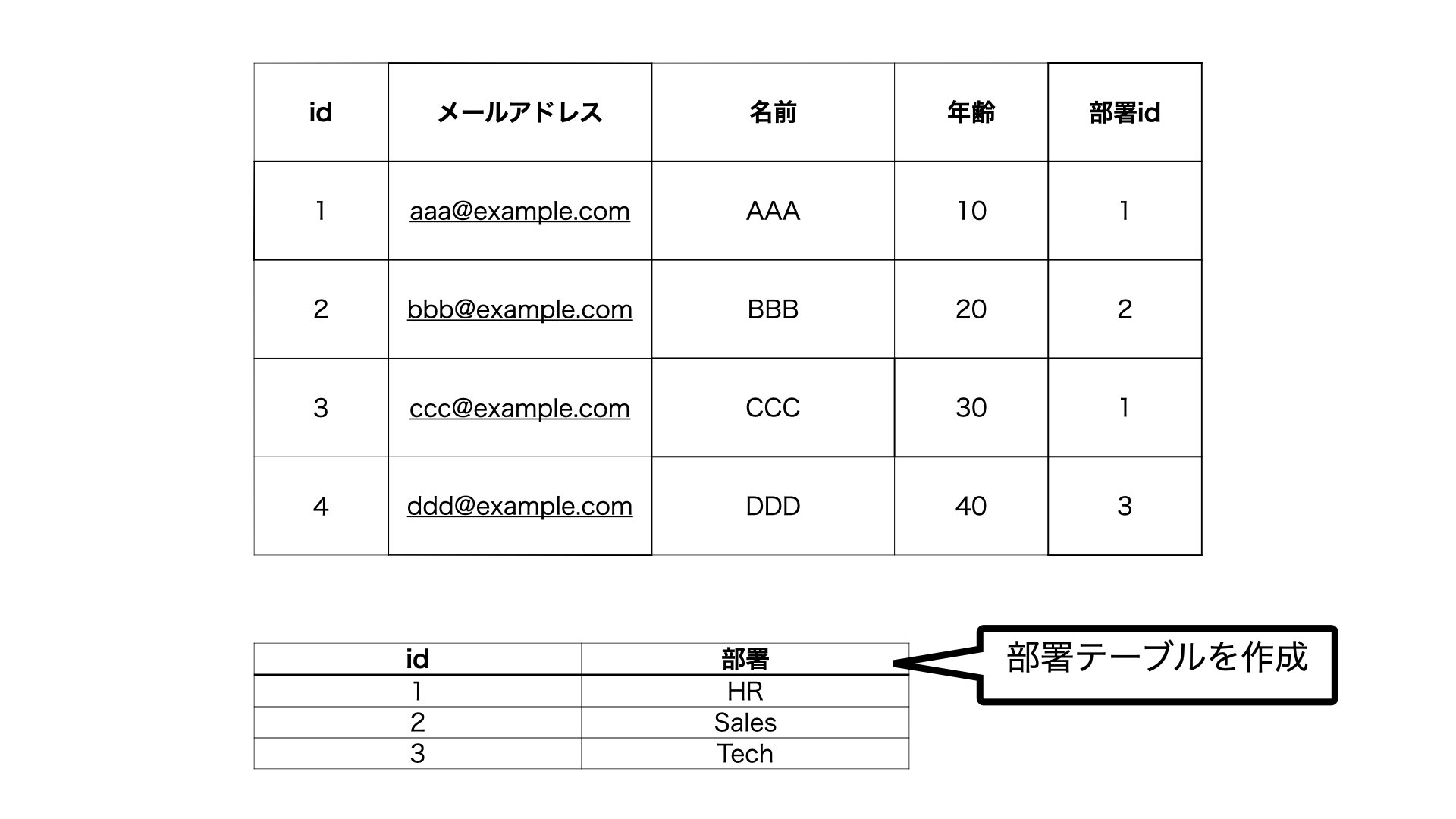
こうすることによって、「HR」という部署名を変えたいとなった場合、部署テーブルの「HR」というフィールド1つだけを変えれば良いことになります。
以上のように、1つの表のカラムの中に、重複するデータが存在する場合は、別のテーブルを用意し、そのテーブルの1ヶ所を変更するだけで全て変更できるようにするのがポイントになります。
このように、データの重複をなくし、データの整合性を保てるようなデータベースを設計する方法のことを「正規化」と言います。
データベースを設計する際は、正規化を行い、データの重複を無くし整合性を保てるようなデータベースを設計することが大切なのです。
リレーショナルデータベースの弱点と「NoSQL」
これまで説明してきたリレーショナルデータベースにも弱点があります。
それは、複雑な業務のシステム化など大規模なシステム開発になればなるほど、データベースが複雑化していくということです。
複雑な業務になることで、データベース内のテーブル数や項目が増加していくことになります。
これはプログラムが複雑化し、処理のスピードが低下する傾向があります。
複雑なデータを管理することができる一方で、大規模なデータになると処理速度が追いつかなくなるというデメリットがあります。
近年のIoTやAIにおいては、大量のデータを管理する必要があります。
今後、膨大なデータを扱うことが想定される将来を見据えた場合、必ずしもリレーショナル型データベースが望ましいとは言い切れません。
また、管理するデータの種類も、従来のような文字列、数値といったデータではなく、画像や音声といったデータ(非構造化データ)も対象となります。
そこで注目されているのが「NoSQL」と呼ばれるデータベースです。
NoSQLとは、SQL言語を使用せずに利用できるデータベースのことです。
NoSQLは、非構造化データの管理において、リレーショナルデータベースよりもコストやパフォーマンスに優れています。
今後は、NoSQL型のデータベースを使用する機械は増えてくるでしょう。
注意点としては、リレーショナル型データベースとNoSQLは、どちらが優れているということではありません。
複雑な業務でない限りは、リレーショナル型データベースが良いのは変わりありません。
扱うデータや状況によって、どちらを使うべきかを考える必要があるということを理解しておきましょう。
まとめ:データべースの設計はデータモデリングが大事
本記事では、「【5分で分かる】データモデルとデータベースの設計方法と関係性」というテーマでまとめました。
データベースを作成する一連の過程のことを「データモデリング」と良い、各過程で作成される成果物がデータモデルでした。
データモデリングは、大きく3つの工程でしたね。
2. データベースで管理すべき項目を洗い出す
3. 各データベースに合わせて設計する
実装を想定したデータベースの設計は、データの重複を無くし整合性を保つことを意識するのが大切です。
本記事ではリレーショナル型データベースにフォーカスして設計のポイントを纏めましたが、リレーショナルデータベースにもデメリットがあることも触れました。
将来を見据えた業務、そして扱うデータの種類によってNoSQLを選択するべきかどうかを考えるのが重要です。
データベースの設計の基本的なエッセンスをまとめましたが、本記事でまとめたこと以外にも多くの注意点や学ぶべきポイントが多くあります。
実際にデータベースの設計を問題形式で解いてみると、より知識を深められるかと思います。
データベースをより詳しく学びたい方
- 下記のUdemy講座もおすすめ。キャンペーン期間だと、1,200円で学べます。受講期限も無期限なので自分のペースで学習できるのがメリットです。

