【自然言語処理】Attentionとは何か

✓目次
本記事の対象者
・ RNNやLSTM、Seq2Seqを活用した自然言語処理に関する知識(one-hot表現、分散処理など)を理解している人 ・ Transformerを理解していることが望ましいです。
Attentionとは
Attentionとは、一言でいうと文章中のどの単語に注目すればよいのかを表すスコアです。
Attentionは、Query, Key, Valueという3つの要素に分かれて計算されます。
Queryとは、Inputデータであり、入力データの中で検索したいものを表します。
Keyとは、検索すべき対象とQueryの近さを図るために使用します。どれだけ似ているかを図るために使用します。
Valueとは、Keyに基づいて適切なValueを出力する要素です。
少し複雑ですが、Attentionとは何かをより詳しく見てみます。以下の図に、Attentionの構造をまとめます。
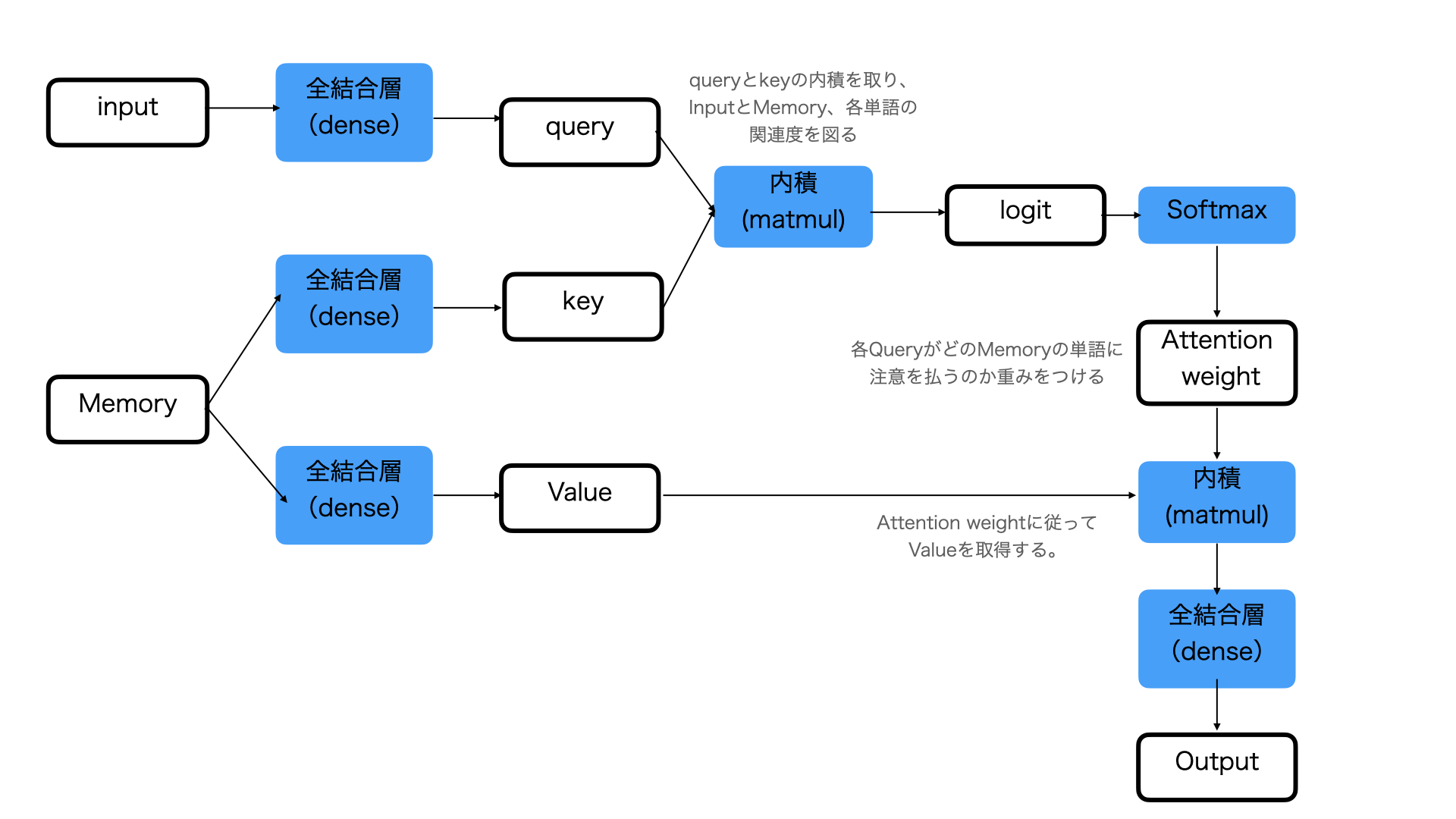
黒線の四角はベクトルまたはテンソルを示し、青い四角は処理を表しています。
Inputというのは、入力である文章に相当します。
当然、自然言語で記述された文章ではなく、単語の分散表現で一定の次元に変換されたベクトルに変換されたものです。
これを埋め込みベクトルと言ったりします。
具体的には、「好き」、「な」、「アニメ」、「は」といった単語に分けられ、それぞれの単語にidが割り当てられています。
Memoryというのは、Inputデータに対する元データになります。具体的には、「ドラゴンボール」、「が」、「好き」といった具体のものです。これも、各単語はidで表されます。
まず、Inputが全結合層で処理を行い、各単語のQueryを作成します。
そして、Memoryを全結合層に入れてKeyを作成し、QueryとKeyで内積を取っています。
内積を取ることでQueryとKeyの類似度/関連度を計算するのです。結果として、InputとMemoryの各単語の関連度を計算することができます。
そしてこの関連度は、Softmax関数に入れられます。
Softmax関数は、Sigmoid関数を使用しており、主に確率を表現するために使われる関数です。
Softmax関数を適用すると、値の範囲を0から1に収めることができます。
そして、0から1の範囲に収められた関連度が、attention_weightになります。これは、Memoryのどの単語に注意を向けるかの重みをつけることになります。
QueryとKeyのベクトルが似ていれば、Attention_weightは大きくなりそうでなければ小さくなります。

このようにして、このニューラルネットワークは、学習していくことになります。
また、memoryから全結合層を介して、Valueが作られます。Valueは、Memoryの各単語を表す埋め込みベクトルです。
この埋め込みベクトルをAttention_weightとの間で内積を取っています。
具体的にこの例で述べると、「ドラゴンボール」というValueにアニメに対するAttention_weightである0.7を掛けた値と「が」というValueにアニメに対するAttention_weightである0.03を掛けた値と、「好き」というValueにアニメに対するAttention_weightである0.34を掛けた値を全部足し合わせた値になります。
こうすることで、もっとも関連度の高い「ドラゴンボール」という単語をそのものを出力するのではなく、他の単語との関係性も考慮することができるということになります。
そして全結合層に入れて、outputを得ることができます。
Attentionというのは奥が深く、実はここで説明したもの以外の他に様々なタイプのものが存在します。
以降は主に、Transformerに関わる以下の4つに着目して整理します。
- Self-Attention
- SourceTarget-Attention
- Multi-Head Attention
- Masked Multi-Head Attention
Self-Attention
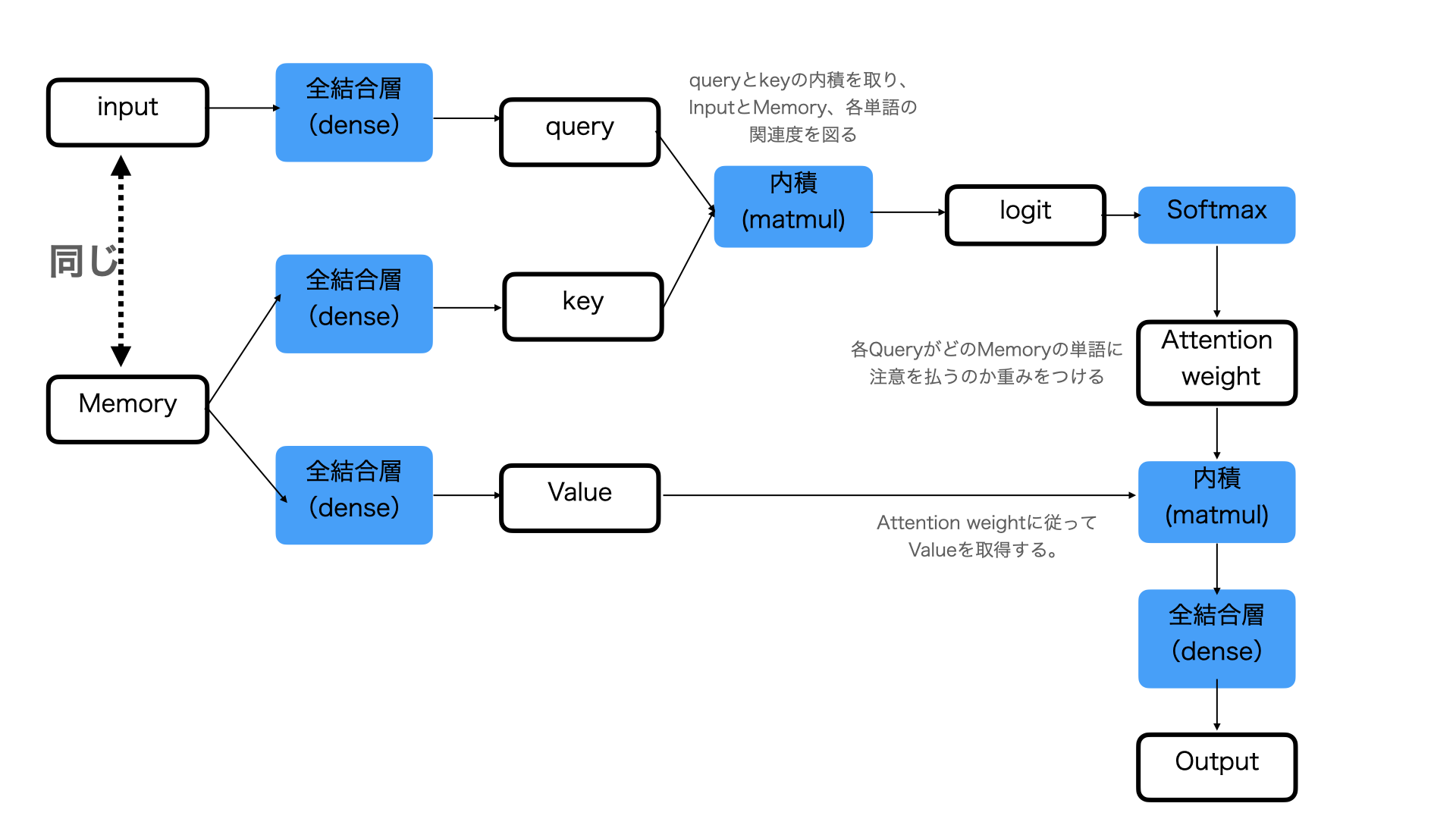
Self-Attentionは、InputとMemoryが同一のAttentionです。
Self-Attentionは、文法の構造だったり、単語同士の関係性を得るために使われます。
SourceTarget-Attention
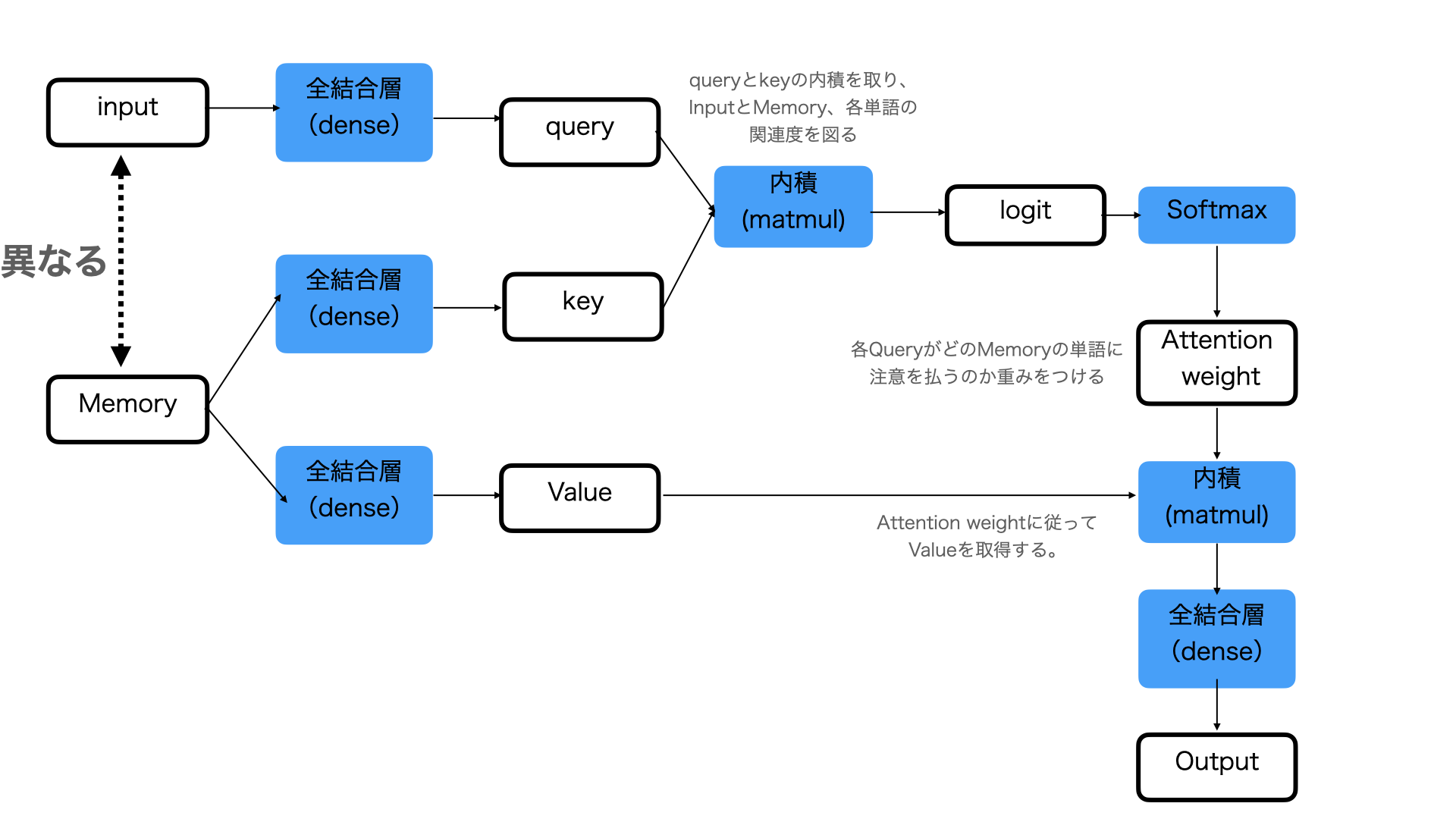
SourceTarget-Attentionは、InputとMemoryが異なるAttentionです。
Transformerにおいて、Encoderの出力とDecoder側の入力からの流れで合流する箇所があるのですが、そこでSourceTarget-Attentionが用いられています。
Multi-Head Attention
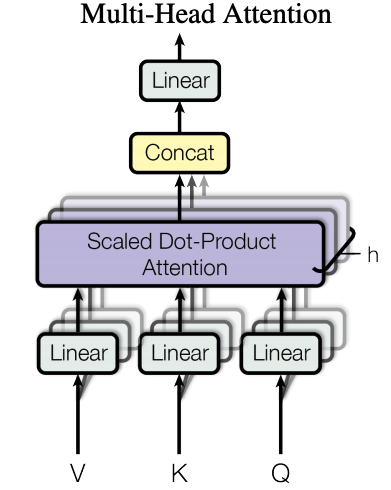
Multi-Head Attentionは、Attentionを平行に並べたものです。図における「V」はValueで、「K」はKey, 「Q」はQuery, です。
Concatというのは、結合を意味します。
そして、Multi-Head Attentionにおいて、それぞれのAttentionはHeadと呼ばれています。
なぜこのようにAttentionを並列に並べるのかというと、性能が向上するからです。
機械学習では、アンサンブル学習という分野があります。これは複数の機械学習モデルを並列に並べて機能させることです。これにより、性能が向上することが知られています。
Masked Multi-Head Attention
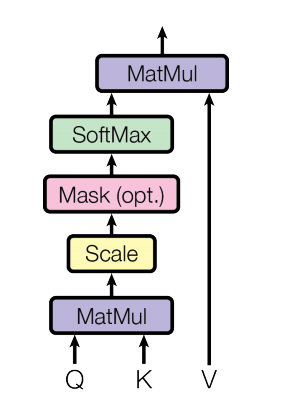
Masked Multi-Head Attentionは、特定のkeyに対して、Attention weightを0にする処理です。
Transformerでは、Decoderで、このMasked Multi-Head Attentionが用いられています。Transformerで、Masked Multi-Head Attentionが行われる理由は、入力した単語の先読みである「カンニング」を防ぐためです。
そのため、入力に予測すべき結果が入らないように、情報をMASKで遮断し、未知のデータに対して正しく予測することができなくなることを防いでいるのです。
まとめ
- Attentionとは何か
- Attentionとは、一言でいうと文章中のどの単語に注目すればよいのかを表すスコアです。
- Query, Key, Valueという3つの要素に分かれて計算され
- Query: Queryとは、Inputデータ。入力データの中で検索したいものを表します。
- Key: 検索すべき対象とQueryの近さを図るために使用します。
- Value: Keyに基づいて適切なValueを出力する要素です。
- Attentionには複数の種類があり用途も様々
- Self-Attention: InputとMemoryが同一のAttention。文法の構造だったり、単語同士の関係性を得るために使われます。
- SourceTarget-Attention: InputとMemoryが異なるAttention。Transformerにおいて、Encoderの出力とDecoder側の入力からの流れで合流点。
- Multi-Head Attention: Attentionを平行に並べたものです。Attentionを並列に並べて性能を向上させる。
- Masked Multi-Head Attention: 特定のkeyに対して、Attention weightを0にする処理。入力した単語の先読みである「カンニング」を防ぐ。
参考文献
- Attention is All You Need, Ashish. V. et al, (2017) - [技術ブログ \| アクセルユニバース株式会社](https://www.acceluniverse.com/blog/developers/2019/08/attention.html)より詳しく学びたい方
- 以下の、Udemyのコースがおすすめです。セール時は、2000円で購入可能であり、30日間の返金保証もついているので、是非試してみてください。
BERTによる自然言語処理を学ぼう! -Attention、TransformerからBERTへとつながるNLP技術-![]()
- AIエンジニアを目指す方は、キカガクがおすすめ。

![]()

