【自然言語処理】Transformerとは何か

当ページのリンクには広告が含まれています。
✓目次
この記事の対象者
・ RNNやLSTM、Seq2Seqを活用した自然言語処理に関する知識(one-hot表現、分散処理など)を理解している人
RNNの基礎については以下の記事でまとめているので参照してください。
Transformerとは
ディープラーニングモデルの一つで、主に自然言語処理の分野で使用されます。
自然言語処理などの時系列データを処理するように設計されてますが、RNNで用いる再帰を用いていません。
ではどのような仕組みなのかというと、大きくはEncoderとDecorderの2つで構成されています。
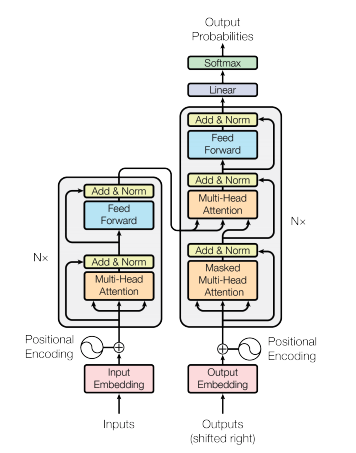
もう一つの特徴としては、Attention層のみで構築されています。
以降、EncoderとDecoderに分けて、その構造を解説したいと思います。
TransformerのEncoderの構造
Encoderでは、Embedding層により入力文章をベクトルに圧縮変換をしています。要するに、自然言語で記述された文章を、単語の分散表現で一定の次元に変換したベクトルに変換をしています。
これを、埋め込みベクトル、といいます。
そして、Positional Encodingによって、単語が文章中のどの位置にあるかの位置情報を加えています。
Multi-Head Attention層とは、その名の通り複数のAttentionが並んでいる領域であり、ここで入力で与えられた各単語との関連度を計算しています。Attentionについては、以下の記事で詳しくまとめていますので、こちらを参照ください。
Add & Normという箇所は、Normalization(正規化)などであり、要はデータの偏りを無くす処理を行っています。
Feed Forwardという部分は、Positionwise fully connected feed-forward networkというものであり、2つの層からなる全結合ニューラルネットワークです。
具体的には、2つの層からなるニューラルネットワークでは、まず入力に重みを掛けてバイアスを足し、活性化関数のReLUに入れる処理を行っています。つまり、0より小さければすべて0にし、0より大きければそのままの値を出力しています。これに重みを掛けて、さらにバイアスを足す、という2層構造のニューラルネットワークになっています。
ちなみにこれらは、単語毎に個別の順伝播を行うニューラルネットワークになっています。こうすることで、他の単語との影響関係を排除することができるのです。
そして再びadd & Normで正規化を行っています。
そして、Multi-Head AttentionとFeed Forwardの箇所は、6回処理が繰り返し行われます。
TransformerのDecoderの構造
まず、Embedding層で、入力文章をベクトルに圧縮します。その後、Positional Encoding層によって位置情報を加えています。このあたりは、Encoderと同じです。
そして、Masked Multi-Head Attention層というのが現れます。これもAttentionの一種です。ここでは、特定のKeyに対してAttention weightを0にする処理が行われます。これを行うことで入力した単語の先読みを、すなわち「カンニング」が行われてしまうことを防いでいるのです。この処理を行わないと、入力に基づいて学習が行われてしまい、未知のデータに対して正しく予測することができなくなってしまいます。
Masked Multi-Head Attentionの後、正規化を行い、Multi-Head Attention層に入ります。ここで、Encoderからの出力を受け付けています。Decoderからの流れと、Encoderからの流れがここで合流しています。
そして正規化を行い、次はPositionwise fully connected fedd-forward networkで処理されます。その後、再び正規化が行われています。
最後に、全結合層であるLinearがあり、Softmax関数で値の範囲を0から1の範囲に収めています。
まとめ
- Transformerとは、
- ディープラーニングモデルの一つで、主に自然言語処理の分野で使される。
- 自然言語処理などの時系列データを処理するように設計されている。しかし、RNNで取り入れている再帰を用いていません。
- 構造としては、EncoderとDecoderの2つで構成されています。
参考文献
- Attention is All You Need, Ashish. V. et al, (2017)
より詳しく学びたい方
- 以下の、Udemyのコースがおすすめです。セール時は、2000円で購入可能であり、30日間の返金保証もついているので、是非試してみてください。
- AIエンジニアを目指す方は、以下の無料カウンセリングを受けてみてはいかがでしょうか?


