【翻訳技術】seq2seqを実装しながら理解してみた

当ページのリンクには広告が含まれています。
✓目次
本記事の対象者
・ pythonの基本を理解している人。
・ Kerasでニューラルネットワークを作ったことがある人
RNNの基礎については以下の記事でまとめているので参照してください。
また、実行環境としてはJupyter Notebookになります。以下の記事に従って環境構築していただければと思います。
今回は、Kerasを使ってseq2seqを構築し、コサイン関数をサイン関数に変換(翻訳)してみたいと思います。
seq2seqとはなにか
seq2seqは、シーケンスを受け取り別のシーケンスに変換するモデルのことで、文章などの入力を圧縮するencoderと、出力を展開するdecoderからなります。
「私はペンを持っている」という文章を、「I have a pen」という英文に翻訳することが可能となります。
encoderとdecoderに、それぞれRNNの層が構築され、encoderとdecoderが接続させることによってseq2seqが作られます。
seq2seqの仕組みについては以下の記事が大変分かりやすいので、参考にしてください。こちらでまとめられている絵を見ながら、以降の記事を読んでいただくと、それぞれのコードがどの領域の実装なのかがイメージしやすくなると思います。
https://sinyblog.com/deaplearning/seq2seq-001/#i
少々複雑に聞こえるかもしれませんが、今回は簡単な例としてcos関数をsin関数に翻訳する形で、その構造を理解したいと思います。
訓練用のデータを作成する。
cos関数の値をencoderへの入力、sin関数の値をdecoderへの入力とします。
なお、正解は、sin関数になります。
decoderへの入力というのは正解から1つ後の時刻にずらした値になります。これは、ある時刻におけるdecoderの出力が、次の時刻における入力に近づくように学習をさせるためです。
このように、ある時刻における正解が次の時刻の入力となる手法を教師強制と言います。
まずは、cos関数とsin関数を作成してプロットしてみます。
1 | %matplotlib inline |
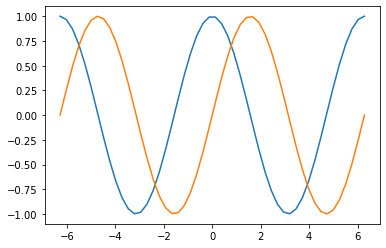
次に、encoderへの入力、decoderへの入力、decoderの正解を作成します。
今回、時系列の数は10に設定しておきます。
zerosメソッドでエンコーダー、デコーダー、正解の形状を作成します。
今回はすべて同じ形状にする。
1 |
|
x_encoderには、コサイン関数の値を入れていき、x_decoderにはサイン関数の値を入れていきます。
この時、x_decoderに入れるサイン関数は、1つ後の時刻にずらす必要があります。時系列で1以降の値に代入するので最初の値は0のままということになります。
1 |
|
続いて正解データであるt_decoderを作成します。
t_decoderには、サイン関数の値をそのまま入れます。
1 |
|
KerasにおけるRNNの入力の形状にするために、x_encoder, x_decoder, t_decoderの形状を、サンプル数、時系列の数、入力層のニューロン数という形状に変更しておきます。
1 | x_encoder = x_encoder.reshape(n_sample, n_rnn, 1) # (サンプル数、時系列の数、入力層のニューロン数) |
これで、データの準備はOKです。
seq2seqの構築
Kerasを使ってseq2seqを構築していきます。
seq2seqの特徴は、学習用のモデル構築と予測用のモデル構築の2つのモデル構築を別々で行う点にあります。
学習用のモデルと予測用のモデルの中に、それぞれencoderとdecoderが存在します。
この特徴を踏まえ、以下のような流れで作成を進めていきます。
2. 学習用モデル構築(encoderの構築)
3. 学習用モデル構築(decoderの構築)
4. 学習用モデル構築(モデルのコンパイル)
5. 学習用モデル構築(構築した学習用モデルを用いて学習を実施)
6. 学習用モデル構築(学習の推移を確認する。)
7. 予測用モデル構築(encoderのモデルを構築)
8. 予測用モデルの構築(decoderのモデルを構築)
9. 翻訳用の関数を定義
それでは一つ一つ順を追ってseq2seqを構築していきたいと思います。
1. 学習用モデル構築(ライブラリのインポートとモデルの設定)
これまで、RNNやLSTMを構築した際は、Sequentialクラスを使用してましたが、今回は、Modelクラスを使います。
Modelクラスを用いることで、複数の経路の入力を持つニューラルネットワークを構築することが可能だからです。
また状態を渡すことでRNN同士を接続することもできます。
今回のseq2seqのRNN部分にはLSTMを使おうと思います。
各種ライブラリをインポートしていますが、今回はInputというのも導入します。
Inputは、入力層を表すライブラリです。
モデルの設定をしていきます。入力層のニューロン数は1、中間層のニューロン数は20、出力層のニューロン数は入力層のニューロン数と同じにします。
1 | from keras.models import Model |
こちらのコードで各種ライブラリのインポートと、モデルの設定は完了です。
2. 学習用モデル構築(encoderの構築)
最初にInputを使ってencoderの入力層を設定します。
Inputを使用する際は、入力の形状を設定する必要があります。時系列数, 入力層のニューロン数を指定しますので、n_rnn, n_inとします。
1 | encoder_input = Input(shape=(n_rnn, n_in)) |
続いてencoderにLSTMを設定します。中間層のニューロン数を設定し、return_stateをTrueに設定します。
return_stateをTrueに設定すると、その時刻における出力と共に状態を得ることができます。
LSTMにおける出力\(h_{t}\)と状態であるメモリセルを得ることができるということです。
1 | encoder_lstm = LSTM(n_mid, return_state=True) |
そして、このencoderのLSTMに、先ほどのencorderの入力を渡します。その結果得られるのは、encoderの出力とencoderの状態\(h\)とencoderの状態\(c\)になります。
LSTMの内部に\(h\)と\(c\)という2つの状態を持っている点については、以下の記事で詳しくまとめらていますので、詳細が知りたい方は参考にしてください。
https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67ca
1 | encoder_output, encoder_state_h, encoder_state_c = encoder_lstm(encoder_input) |
この2つの状態\(t\)と\(c\)は、リストでまとめておき、encoder_stateとしておきます。
1 | encoder_state = [encoder_state_h, encoder_state_c] |
これでencoderは完成です。
3. 学習用モデル構築(decoderの構築)
まずInputを用いて、decoderの入力層を作ります。
1 | decoder_input = Input(shape=(n_rnn, n_in)) |
encoderの時と同様、LSTMの層を作ります。こちらも先ほど同様に、return_stateをTrueにしておきますが、return_sequencesもTrueにしておきます。
このようにすることで、すべての時系列の出力を出力として得ることができます。
1 | decoder_lstm = LSTM(n_mid, return_sequences=True, return_state=True) |
decoderのLSTMには、先ほど作成したdecoder_inputを入れます。その際に初期状態であるinitial_stateに先ほどのencoder_stateに設定します。
その結果返ってくるのが、decoderの出力と2つの状態です。
この段階で、decoderから出力された状態は使わないので、とりあえず_をいれておきます。
1 | decoder_output, _, _ = decoder_lstm(decoder_input, initial_state=encoder_state ) |
LSTM層の次に、全結合層であるDenseを入れます。
Denseには出力層のニューロン数を設定します。活性化関数は、ひとまずlinearとしておきます。linearは恒等関数を意味します。
1 | decoder_dense = Dense(n_out, activation='linear') |
そして、このdecoder_denseにdecoder_outputを入れることでdecoderの出力を得ることができます。
1 | decoder_output = decoder_dense(decoder_output) |
decoderの構築はこれで完了です。
4. 学習用モデル構築(モデルのコンパイル)
まずはseq2seqにおける学習用のモデルを構築していきます。
Modelクラスを用いてモデル構築を行います。
Modelクラスは、全体の入力と出力のみ設定すればOK、という優れものです。
入力が複数存在する場合は、リストを使って設定すればOKです。
入力は、encoder_inputとdecoder_inputの2つになります。
そして全体の出力は、decoder_outputになるので、コードとしては以下となります。
1 | model = Model([encoder_input, decoder_input], decoder_output) |
次にモデルのコンパイルを実施します。
コンパイルの際は、損失関数とと最適化アルゴリズムを指定する必要があります。
損失関数は回帰の場合は、二乗誤差で、分類の場合はクロスエントロピーが提供されるのが一般的です。
今回は、encoderの入力から、学習した結果に基づいて翻訳結果を予測するので、二乗誤差を適用します。
最適化アルゴリズムは、収束しやすいadamでもいいですが、sgdを適用してみたいと思います
これでモデル構築は完了なので、print(model.summary())で、構築したモデルの概要を確認したいと思います。
1 | model.compile(loss="mean_squared_error", optimizer="sgd") |
encoderの入力とdecoderの入力があります。
また、encoderのLSTMとdecoderのLSTMがあります。decoderの方は、全結合層であるDenseを1つ所持していることが確認できます。
5. 学習用モデル構築(構築した学習用モデルを用いて学習を実施)
RNNの時と同様にfitメソッドを使用して学習を行います。
入力は、x_encoderとx_decoderとし、正解は、t_decoderを指定します。
バッチサイズを10とし、エポック数を30に設定します。
1 | history = model.fit([x_encoder, x_decoder], t_decoder, |
6. 学習用モデル構築(学習の推移を確認する。)
以下のコードでグラフで誤差の収束具合を確認します。
1 | loss = history.history['loss'] |
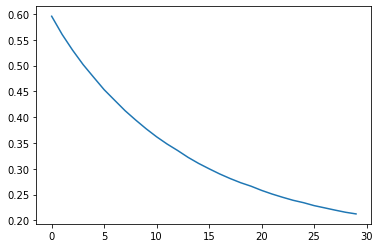
んー、収束しきってない気がします。
7. 予測用モデル構築(encoderのモデルを構築)
seq2seqでは、訓練用のモデルと、予測用のモデルを別々に構築する必要があります。
予測用モデルは、学習済みのオブジェクトから、encoder, decoderのモデルを構築します。
encoderは入力を受け取り状態を返し、decoderは入力と状態を受け取って出力と状態を返すようにします。
まずはModelクラスを用いてencoderのモデルを構築します。
入力としてencoder_input、出力としてencoder_stateを設定します。
encoder_inputとencoder_stateの間には、encoder_lstmが存在する構造をとっています。このencoder_lstmは先ほどの学習済みのLSTMになります。
これだけで、予測用モデルにおけるencoderは完成します。
1 | encoder_model = Model(encoder_input, encoder_state) |
8. 予測用モデルの構築(decoderのモデルを構築)
続いて予測用モデルのdecoderを構築します。
入力層は、新規にInputを使って作成します。形状は、時系列の長さ、入力層のニューロン数を設定します。
今回は、時系列の長さは1で入力層のニューロン数はn_inで設定しているので、以下のようになります。なお、時系列の長さが可変である場合は、Noneを設定します。
1 | decoder_input = Input(shape=(1, n_in)) |
LSTMには内部に2つの状態を持つので、状態の入力を2つ作ります。
この2つの状態は、decoder_state_in_hとdecoder_state_in_cとします。
それぞれの状態の数は、中間層のニューロンの数と同じになります。
これらは、1つのリストにまとめて、decoder_state_inとしておきます。
1 | decoder_state_in_h = Input(shape=(n_mid,)) |
次に先ほどのdecoder_lstmにdecoder_inputとdecoder_state_inを設定します。decoder_state_inは、初期状態として設定するので、initial_stateとしておきます。
decoder_lstmも同様、既存の学習済みのLSTMになります。
1 | decoder_output, decoder_state_h, decoder_state_c = decoder_lstm(decoder_input, initial_state=decoder_state_in) |
得られたdecoder_state_hとdecoder_state_cは、以下のようにリストにし、そのうえで、decoder_denseにdecoder_outputを入れて、decoderの出力を得ることができます。こちらも、すでに学習済みのDenseになります。
1 | decoder_state = [decoder_state_h, decoder_state_c] |
いよいよ、decoderのモデルを構築します。
モデル化の際に、入力として渡すのは、decoder_inputとdecoder_state_inです。
出力は、decoder_outputとdecoder_stateになります。
それぞれ、リストとして値を保持しており、入力として渡す際は、各リストを結合して渡すので、+でリストを結合しています。
1 | decoder_model = Model([decoder_input] + decoder_state_in, [decoder_output] + decoder_state) |
9. 翻訳用の関数を定義
コサイン関数を翻訳して、サイン関数に変換するための関数を定義します。
encoderへの入力値であるinput_dataを渡し、予測用モデルに適用した翻訳結果を返す処理を定義します。
1 | def translate(input_data): |
コサイン関数をサイン関数に翻訳
1 | idices = range(0, 40) |
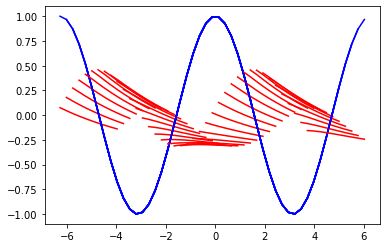
翻訳の結果としては少々いまいちでした。
epoc数を30ではなく50に増やして再度翻訳してみます。
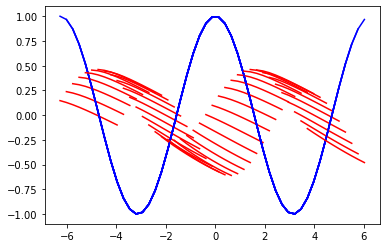
まだ微妙ですね。思い切ってepoc数を100に増やして再度実施してみます。
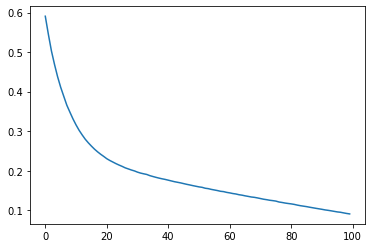
収束しきっているようなしていないような微妙な感じです。翻訳までさせてみると以下のような感じです。
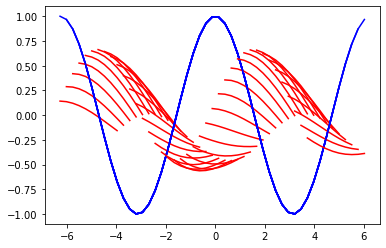
どうやらこの三次元的なコサインカーブはどうにもならないみたいですね。
こんな時は、最適化アルゴリズムをsgdではなく別のものを適用すると改善される可能性が高いです。もしくは、通常のニューラルネットワークとかですと、中間層のニューロン数を増やしたり、層を増やしたりするのもある程度完全が見込めるかもしれません。
最終手段としてはデータの中心化(バッチノーマリゼーション)と言われる処理をするとよくなるパタンが多いそうです。
今回は、KerasのDocumentationにて記載のある最適化アルゴリズムの中で、Adagradという最適化アルゴリズムを適用してみたいと思います。
以下のように、Adagradという風にするだけです。エポック数は100のままにしています。
1 | model.compile(loss="mean_squared_error", optimizer="Adagrad") |
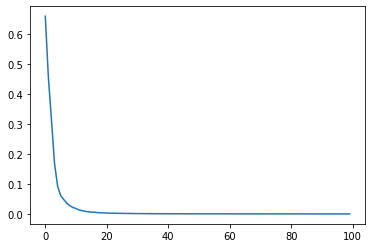
誤差の収束具合は以下の通りです。(さっきと全然違う)
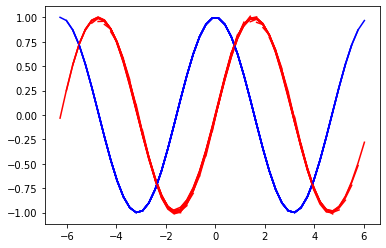
肝心の翻訳結果は以下の通りです。すごい、ちゃんとコサインカーブになりました。
ここまでの知識を活用して、実際に日本語や英語を活用した翻訳にもチャレンジしたい方は、以下のUdemy(オンライン学習プラットフォーム)の講座がおすすめです。視聴期限無しで一流講師への質問も可能です。また講座料金については、30日以内では返金可能ですのでお気軽に試していただければと思います。
>> 自然言語処理とチャットボット: AIによる文章生成と会話エンジン開発![]()

