当ページのリンクには広告が含まれています。
目次
データサイエンス100本ノックの始め方は、以下の記事を参考にしていただければと思います。
>>データサイエンス100本ノックの始め方を確認する
第84問目: 除算エラー対応
P-084: 顧客データフレーム(df_customer)の全顧客に対し、全期間の売上金額に占める2019年売上金額の割合を計算せよ。ただし、販売実績のない場合は0として扱うこと。そして計算した割合が0超のものを抽出せよ。 結果は10件表示させれば良い。また、作成したデータにNAやNANが存在しないことを確認せよ。
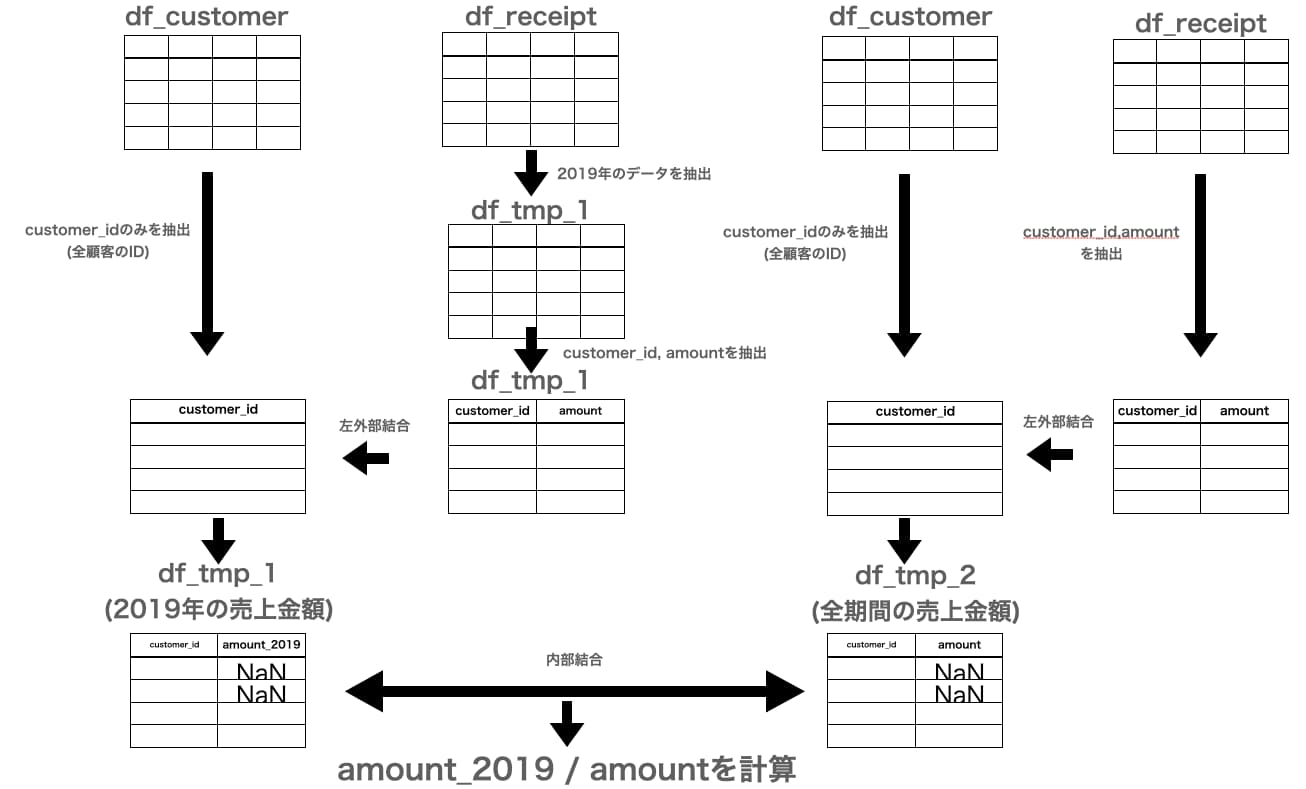
本問の回答の大まかな流れを図とともにまとめます。
まずdf_receiptからqueryメソッドを用いて2019年のデータを抽出しdf_tmp_1とします。
df_tmp_1をdf_customerに左外部結合を行うことで全顧客毎の2019年の売上金額のデータフレームが作成されます。
その一方で全顧客毎の全期間の売上金額のデータフレームをdf_tmp_2としてまとめ、df_tmp_1と内部結合を行い、最後に「2019年の売÷全期間の売上」を計算し割合を抽出します。

ポイントは、割合を算出する際にNaNデータがあることでエラーとなってしまいます。そのため最終的に欠損値がない状態で割合を計算する必要があるので、その点に気をつけましょう。
それでは早速回答していきます。
まずはdf_customerの構造を確認します。
出力1
2
3
4
5
6
7
8
9
10
11
| customer_id customer_name gender_cd gender birth_day age postal_cd address application_store_cd application_date status_cd
0 CS021313000114 大野 あや子 1 女性 1981-04-29 37 259-1113 神奈川県伊勢原市粟窪********** S14021 20150905 0-00000000-0
1 CS037613000071 六角 雅彦 9 不明 1952-04-01 66 136-0076 東京都江東区南砂********** S13037 20150414 0-00000000-0
2 CS031415000172 宇多田 貴美子 1 女性 1976-10-04 42 151-0053 東京都渋谷区代々木********** S13031 20150529 D-20100325-C
3 CS028811000001 堀井 かおり 1 女性 1933-03-27 86 245-0016 神奈川県横浜市泉区和泉町********** S14028 20160115 0-00000000-0
4 CS001215000145 田崎 美紀 1 女性 1995-03-29 24 144-0055 東京都大田区仲六郷********** S13001 20170605 6-20090929-2
5 CS020401000016 宮下 達士 0 男性 1974-09-15 44 174-0065 東京都板橋区若木********** S13020 20150225 0-00000000-0
6 CS015414000103 奥野 陽子 1 女性 1977-08-09 41 136-0073 東京都江東区北砂********** S13015 20150722 B-20100609-B
7 CS029403000008 釈 人志 0 男性 1973-08-17 45 279-0003 千葉県浦安市海楽********** S12029 20150515 0-00000000-0
8 CS015804000004 松谷 米蔵 0 男性 1931-05-02 87 136-0073 東京都江東区北砂********** S13015 20150607 0-00000000-0
9 CS033513000180 安斎 遥 1 女性 1962-07-11 56 241-0823 神奈川県横浜市旭区善部町********** S14033 20150728 6-20080506-5
|
続いてレシート明細データフレーム(df_receipt)の構造を確認します
出力1
2
3
4
5
6
7
8
9
10
11
12
|
sales_ymd sales_epoch store_cd receipt_no receipt_sub_no customer_id product_cd quantity amount
0 20181103 1541203200 S14006 112 1 CS006214000001 P070305012 1 158
1 20181118 1542499200 S13008 1132 2 CS008415000097 P070701017 1 81
2 20170712 1499817600 S14028 1102 1 CS028414000014 P060101005 1 170
3 20190205 1549324800 S14042 1132 1 ZZ000000000000 P050301001 1 25
4 20180821 1534809600 S14025 1102 2 CS025415000050 P060102007 1 90
5 20190605 1559692800 S13003 1112 1 CS003515000195 P050102002 1 138
6 20181205 1543968000 S14024 1102 2 CS024514000042 P080101005 1 30
7 20190922 1569110400 S14040 1102 1 CS040415000178 P070501004 1 128
8 20170504 1493856000 S13020 1112 2 ZZ000000000000 P071302010 1 770
9 20191010 1570665600 S14027 1102 1 CS027514000015 P071101003 1 680
|
まずはdf_receiptから2019年1月1日から2019年12月31日までの期間のデータを抽出したいと思います。
1
2
| df_tmp_1 = df_receipt.query('20190101 <= sales_ymd <= 20191231')
df_tmp_1.head(10)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
|
sales_ymd sales_epoch store_cd receipt_no receipt_sub_no customer_id product_cd quantity amount
3 20190205 1549324800 S14042 1132 1 ZZ000000000000 P050301001 1 25
5 20190605 1559692800 S13003 1112 1 CS003515000195 P050102002 1 138
7 20190922 1569110400 S14040 1102 1 CS040415000178 P070501004 1 128
9 20191010 1570665600 S14027 1102 1 CS027514000015 P071101003 1 680
10 20190918 1568764800 S14025 1182 2 CS025415000134 P070401002 1 138
13 20190326 1553558400 S13016 112 1 CS016215000032 P091401190 1 780
16 20190621 1561075200 S13044 1142 2 ZZ000000000000 P040102001 1 268
18 20190603 1559520000 S14026 1182 1 CS026515000042 P070504016 1 188
19 20190606 1559779200 S13044 1122 1 ZZ000000000000 P071102002 1 190
26 20190810 1565395200 S14034 1122 1 CS034414000034 P071302003 1 318
|
df_tmp_1をdf_customerに左外部結合させていきます。共通カラムはcustomer_idになります。
【解説】外部結合の方法を学ぶ | データサイエンス100本ノック【問38〜問40 回答】 - omathin blog
1
2
3
| # 2. "1"で抽出したデータを顧客データフレーム(df_customer)のcustomer_idに左外部結合する
df_tmp_1 = pd.merge(df_customer['customer_id'], df_tmp_1[['customer_id', 'amount']], how='left', on='customer_id')
df_tmp_1.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount
0 CS021313000114 NaN
1 CS037613000071 NaN
2 CS031415000172 2400.0
3 CS031415000172 258.0
4 CS031415000172 215.0
5 CS031415000172 98.0
6 CS028811000001 NaN
7 CS001215000145 NaN
8 CS020401000016 NaN
9 CS015414000103 208.0
10 CS015414000103 102.0
11 CS015414000103 138.0
12 CS015414000103 118.0
13 CS015414000103 138.0
14 CS015414000103 170.0
15 CS029403000008 NaN
16 CS015804000004 NaN
17 CS033513000180 NaN
18 CS007403000016 NaN
19 CS035614000014 NaN
20 CS011215000048 160.0
21 CS011215000048 88.0
22 CS009413000079 NaN
23 CS040412000191 NaN
24 CS029415000023 130.0
25 CS029415000023 2400.0
26 CS029415000023 60.0
27 CS029415000023 278.0
28 CS029415000023 190.0
29 CS029415000023 178.0
|
df_tmp_1で顧客ID(customer_id)をみると、同じIDが複数のレコードに分かれていることがわかります。
例えば、CS031415000172というデータは、3行目〜6行目の間に含まれています。
そのためcustomer_idごとにamountの合計値を取る必要があるのでgroupbyとsumメソッドを用いて処理していきます。※aggメソッドを用いてもOKです
またamountというカラム名もamount_2019というカラム名に変更しておきます。
>> groupby()メソッドとsum()またはagg()を用いて、各顧客ごとの売上金額の合計を算出する方法を復習する。
1
2
| df_tmp_1 = df_tmp_1.groupby('customer_id').sum().reset_index().rename(columns={'amount':'amount_2019'})
df_tmp_1.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
customer_id amount_2019
0 CS001105000001 0.0
1 CS001112000009 0.0
2 CS001112000019 0.0
3 CS001112000021 0.0
4 CS001112000023 0.0
5 CS001112000024 0.0
6 CS001112000029 0.0
7 CS001112000030 0.0
8 CS001113000004 1298.0
9 CS001113000010 0.0
10 CS001114000005 188.0
11 CS001115000006 0.0
12 CS001115000010 578.0
13 CS001202000023 0.0
14 CS001202000024 0.0
15 CS001202000026 0.0
16 CS001203000021 0.0
17 CS001205000004 702.0
18 CS001205000006 486.0
19 CS001211000003 0.0
20 CS001211000007 0.0
21 CS001211000018 0.0
22 CS001211000024 0.0
23 CS001211000025 456.0
24 CS001212000018 0.0
25 CS001212000027 0.0
26 CS001212000031 0.0
27 CS001212000042 0.0
28 CS001212000045 0.0
29 CS001212000046 0.0
|
レシート明細データフレーム(df_receipt)を顧客データフレーム(df_customer)に左外部結合させます。
1
2
| df_tmp_2 = pd.merge(df_customer['customer_id'], df_receipt[['customer_id', 'amount']], how='left', on='customer_id')
df_tmp_2.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount
0 CS021313000114 NaN
1 CS037613000071 NaN
2 CS031415000172 100.0
3 CS031415000172 320.0
4 CS031415000172 2400.0
5 CS031415000172 448.0
6 CS031415000172 258.0
7 CS031415000172 215.0
8 CS031415000172 88.0
9 CS031415000172 102.0
10 CS031415000172 98.0
11 CS031415000172 278.0
12 CS031415000172 110.0
13 CS031415000172 218.0
14 CS031415000172 268.0
15 CS031415000172 185.0
16 CS028811000001 NaN
17 CS001215000145 680.0
18 CS001215000145 195.0
19 CS020401000016 NaN
20 CS015414000103 130.0
21 CS015414000103 118.0
22 CS015414000103 208.0
23 CS015414000103 102.0
24 CS015414000103 900.0
25 CS015414000103 1100.0
26 CS015414000103 138.0
27 CS015414000103 118.0
28 CS015414000103 138.0
29 CS015414000103 170.0
|
1
2
| df_tmp_2 = df_tmp_2.groupby('customer_id').sum().reset_index()
df_tmp_2.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount
0 CS001105000001 0.0
1 CS001112000009 0.0
2 CS001112000019 0.0
3 CS001112000021 0.0
4 CS001112000023 0.0
5 CS001112000024 0.0
6 CS001112000029 0.0
7 CS001112000030 0.0
8 CS001113000004 1298.0
9 CS001113000010 0.0
10 CS001114000005 626.0
11 CS001115000006 0.0
12 CS001115000010 3044.0
13 CS001202000023 0.0
14 CS001202000024 0.0
15 CS001202000026 0.0
16 CS001203000021 0.0
17 CS001205000004 1988.0
18 CS001205000006 3337.0
19 CS001211000003 0.0
20 CS001211000007 0.0
21 CS001211000018 0.0
22 CS001211000024 0.0
23 CS001211000025 456.0
24 CS001212000018 0.0
25 CS001212000027 448.0
26 CS001212000031 296.0
27 CS001212000042 0.0
28 CS001212000045 0.0
29 CS001212000046 228.0
|
df_tmp_1とdf_tmp_2を内部結合します。
1
2
| df_tmp = pd.merge(df_tmp_1, df_tmp_2, how='inner', on='customer_id')
df_tmp.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount_2019 amount
0 CS001105000001 0.0 0.0
1 CS001112000009 0.0 0.0
2 CS001112000019 0.0 0.0
3 CS001112000021 0.0 0.0
4 CS001112000023 0.0 0.0
5 CS001112000024 0.0 0.0
6 CS001112000029 0.0 0.0
7 CS001112000030 0.0 0.0
8 CS001113000004 1298.0 1298.0
9 CS001113000010 0.0 0.0
10 CS001114000005 188.0 626.0
11 CS001115000006 0.0 0.0
12 CS001115000010 578.0 3044.0
13 CS001202000023 0.0 0.0
14 CS001202000024 0.0 0.0
15 CS001202000026 0.0 0.0
16 CS001203000021 0.0 0.0
17 CS001205000004 702.0 1988.0
18 CS001205000006 486.0 3337.0
19 CS001211000003 0.0 0.0
20 CS001211000007 0.0 0.0
21 CS001211000018 0.0 0.0
22 CS001211000024 0.0 0.0
23 CS001211000025 456.0 456.0
24 CS001212000018 0.0 0.0
25 CS001212000027 0.0 448.0
26 CS001212000031 0.0 296.0
27 CS001212000042 0.0 0.0
28 CS001212000045 0.0 0.0
29 CS001212000046 0.0 228.0
|
ここで欠損値の有無を確認します。
出力1
2
3
4
| customer_id 0
amount_2019 0
amount 0
dtype: int64
|
欠損値は無いようなので、2019年の売上金額/全期間の売上金額を算出し、amount_rateカラムに格納します。
1
2
| df_tmp['amount_rate'] = df_tmp['amount_2019']/df_tmp['amount']
df_tmp.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount_2019 amount amount_rate
0 CS001105000001 0.0 0.0 NaN
1 CS001112000009 0.0 0.0 NaN
2 CS001112000019 0.0 0.0 NaN
3 CS001112000021 0.0 0.0 NaN
4 CS001112000023 0.0 0.0 NaN
5 CS001112000024 0.0 0.0 NaN
6 CS001112000029 0.0 0.0 NaN
7 CS001112000030 0.0 0.0 NaN
8 CS001113000004 1298.0 1298.0 1.000000
9 CS001113000010 0.0 0.0 NaN
10 CS001114000005 188.0 626.0 0.300319
11 CS001115000006 0.0 0.0 NaN
12 CS001115000010 578.0 3044.0 0.189882
13 CS001202000023 0.0 0.0 NaN
14 CS001202000024 0.0 0.0 NaN
15 CS001202000026 0.0 0.0 NaN
16 CS001203000021 0.0 0.0 NaN
17 CS001205000004 702.0 1988.0 0.353119
18 CS001205000006 486.0 3337.0 0.145640
19 CS001211000003 0.0 0.0 NaN
20 CS001211000007 0.0 0.0 NaN
21 CS001211000018 0.0 0.0 NaN
22 CS001211000024 0.0 0.0 NaN
23 CS001211000025 456.0 456.0 1.000000
24 CS001212000018 0.0 0.0 NaN
25 CS001212000027 0.0 448.0 0.000000
26 CS001212000031 0.0 296.0 0.000000
27 CS001212000042 0.0 0.0 NaN
28 CS001212000045 0.0 0.0 NaN
29 CS001212000046 0.0 228.0 0.000000
|
改めて欠損値を確認します。
出力1
2
3
4
5
| customer_id 0
amount_2019 0
amount 0
amount_rate 13665
dtype: int64
|
amount_rateに欠損値が存在しているので保管します。
欠損値の補完はfillnaメソッドを使用します。今回は全て0で補完します。
1
2
| df_tmp['amount_rate'] = df_tmp['amount_rate'].fillna(0)
df_tmp.head(30)
|
出力1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| customer_id amount_2019 amount amount_rate
0 CS001105000001 0.0 0.0 0.000000
1 CS001112000009 0.0 0.0 0.000000
2 CS001112000019 0.0 0.0 0.000000
3 CS001112000021 0.0 0.0 0.000000
4 CS001112000023 0.0 0.0 0.000000
5 CS001112000024 0.0 0.0 0.000000
6 CS001112000029 0.0 0.0 0.000000
7 CS001112000030 0.0 0.0 0.000000
8 CS001113000004 1298.0 1298.0 1.000000
9 CS001113000010 0.0 0.0 0.000000
10 CS001114000005 188.0 626.0 0.300319
11 CS001115000006 0.0 0.0 0.000000
12 CS001115000010 578.0 3044.0 0.189882
13 CS001202000023 0.0 0.0 0.000000
14 CS001202000024 0.0 0.0 0.000000
15 CS001202000026 0.0 0.0 0.000000
16 CS001203000021 0.0 0.0 0.000000
17 CS001205000004 702.0 1988.0 0.353119
18 CS001205000006 486.0 3337.0 0.145640
19 CS001211000003 0.0 0.0 0.000000
20 CS001211000007 0.0 0.0 0.000000
21 CS001211000018 0.0 0.0 0.000000
22 CS001211000024 0.0 0.0 0.000000
23 CS001211000025 456.0 456.0 1.000000
24 CS001212000018 0.0 0.0 0.000000
25 CS001212000027 0.0 448.0 0.000000
26 CS001212000031 0.0 296.0 0.000000
27 CS001212000042 0.0 0.0 0.000000
28 CS001212000045 0.0 0.0 0.000000
29 CS001212000046 0.0 228.0 0.000000
|
最後に計算した割合が0以上となっているデータのみを抽出し10件出力されば完了です。
1
| df_tmp.query('amount_rate > 0').head(10)
|
出力1
2
3
4
5
6
7
8
9
10
11
| customer_id amount_2019 amount amount_rate
8 CS001113000004 1298.0 1298.0 1.000000
10 CS001114000005 188.0 626.0 0.300319
12 CS001115000010 578.0 3044.0 0.189882
17 CS001205000004 702.0 1988.0 0.353119
18 CS001205000006 486.0 3337.0 0.145640
23 CS001211000025 456.0 456.0 1.000000
30 CS001212000070 456.0 456.0 1.000000
57 CS001214000009 664.0 4685.0 0.141729
59 CS001214000017 2962.0 4132.0 0.716844
61 CS001214000048 1889.0 2374.0 0.795703
|
まとめ: データサイエンス100本ノック【問84 回答】で除算エラー対応を学びました
本記事で紹介した方法を元にデータサイエンティストとしての知見を深めていただければと思います。
なお、データサイエンティストに必要な知識は、TechAcademyのデータサイエンスコースでの学習がおすすめです。